How AI Can Degrade Human Performance in High-Stakes Settings
Across disciplines, bad AI predictions have a surprising tendency to make human experts perform worse.
Jul 15, 2025


Last week, the AI nonprofit METR published an in-depth study on human-AI collaboration that stunned experts. It found that software developers with access to AI tools took 19% longer to complete their tasks, despite believing they had finished 20% faster. The findings shed important light on our ability to predict how AI capabilities interact with human skills.
Since 2020, we have been conducting similar studies on human-AI collaboration, but in contexts with much higher stakes than software development. Alarmingly, in these safety-critical settings, we found that access to AI tools can cause humans to perform much, much worse.
A 19% slowdown in software development can eat into profits. Reduced performance in safety-critical settings can cost lives.
Imagine that you’re aboard a passenger jet on its final approach into San Francisco. Everything seems ready for a smooth landing — until an AI-infused weather monitor misses a sudden microburst. Neither the crew nor the autopilot is warned that the aircraft is no longer configured to generate enough lift. By the time the crew notices the anomaly, the aircraft is losing altitude, and fast! Now the crew has twice the work to do in half the time. They throttle up aggressively to regain altitude while simultaneously redirecting the autopilot to fly a go-around. After a close call, when the weather risk is over, the jet lands safely.
Or picture being a nurse, working the night shift in the surgical wing of an understaffed hospital. As usual, alarms have been going off all night — most of them when nothing is wrong. An AI-infused dashboard helps you determine which alarms indicate serious danger, rating patient vitals by the second. Tonight, the dashboard tags one chart as “low risk.” You move on to other patients. Minutes later, an alarm tells you that the patient’s oxygen levels have plunged dangerously low. You scramble and manage to stabilize the patient. Afterward, you notice that the AI algorithm had missed a slow but steady increase in the patient’s heart rate over several hours: a subtle warning of impending collapse.
Lastly, envision that you are an engineer in the control room of a nuclear power plant. Staffing has been sharply reduced now that you work alongside an AI-augmented warning system. The AI warning system prioritizes the most critical alarms and filters out false or irrelevant alarms, which inadvertently hides an underlying problem: it mislabels a gradual drop in coolant pressure as benign. As the anomaly spreads, more subsystems begin to malfunction. You take actions, but they are ineffective. As the problem gets worse, you call for assistance. By the time help arrives, you’re rushing to avert a partial core meltdown. While you and your human teammates manage to prevent the meltdown, the damage sustained will delay the restart of the plant for weeks.
These snapshots from aviation, health care, and nuclear energy highlight a key fact: AI is never deployed in isolation. It’s integrated into existing technologies, processes, and — most importantly — human workflows.
Hidden risks in human-AI workflows. While AI infusions can match or even exceed unaided human performance, integrating these systems into real-world workflows also introduces hidden vulnerabilities. Standard guidance frameworks — like the NIST AI Risk Management Framework and Article 14 of the EU AI Act — call for human oversight, but they stop short of examining how AI shapes human decision-making in collaborative settings.
/inline-pitch-cta
Our latest research, published last month in npj Digital Medicine, shows that even the most carefully designed human-AI collaborations can have unpredictable blind spots. In safety-critical settings such as aviation, health care, and nuclear energy, such blind spots can have catastrophic consequences.
Flawed metrics. Most safety evaluations fail by treating AI and humans separately, or they boil down the complex effects of collaboration into a single metric, like “average performance.” That approach hides blind spots, with outsized ramifications: average gains can mask rare but severe failures, while frequent small benefits can come at the cost of rare but catastrophic events.
We developed Joint Activity Testing to address the limitations of these standard methods for evaluating AI-infused technologies. Our method measures how AI impacts human performance across a range of escalating, domain-specific challenges. It provides decision-makers with data showing how strong, mediocre, and poor AI performance in a given task may impact the performance of human collaborators. This has led to a further, perhaps even more serious discovery: human experts often struggle to recognize and recover from AI mistakes, which is an especially critical capability in high-risk settings.
Our experiments with Joint Activity Testing have shown us how AI assistance can improve outcomes in some situations but degrade them in others. Unlike the overly broad assessments provided by existing frameworks, our findings offer clear, targeted feedback for redesign and improvement.
AI in healthcare case study. Since 2020, we’ve used Joint Activity Testing to stress-test human-AI teams in real-world scenarios. In our latest study, 450 nursing students and a dozen licensed nurses each reviewed 10 historical ICU cases, using an AI early warning tool in four configurations:
AI’s influence on human expertise. We found that AI predictions strongly influenced how the nurses assessed their patients, for better and for (much) worse. The nurses were asked to rate each ICU case on a scale of 1-10, based on how concerned they were about the patient’s well-being. Higher concern for emergency patients and lower concern for non-emergency patients indicated better performance. When AI predictions were most correct, nurses performed 53% to 67% better than when they worked without AI assistance. However, when AI predictions were most misleading, nurses performed 96% to 120% worse than when they worked without AI assistance. Adding annotations to AI predictions did not significantly alter results. Annotations alone had a similar but dampened effect.
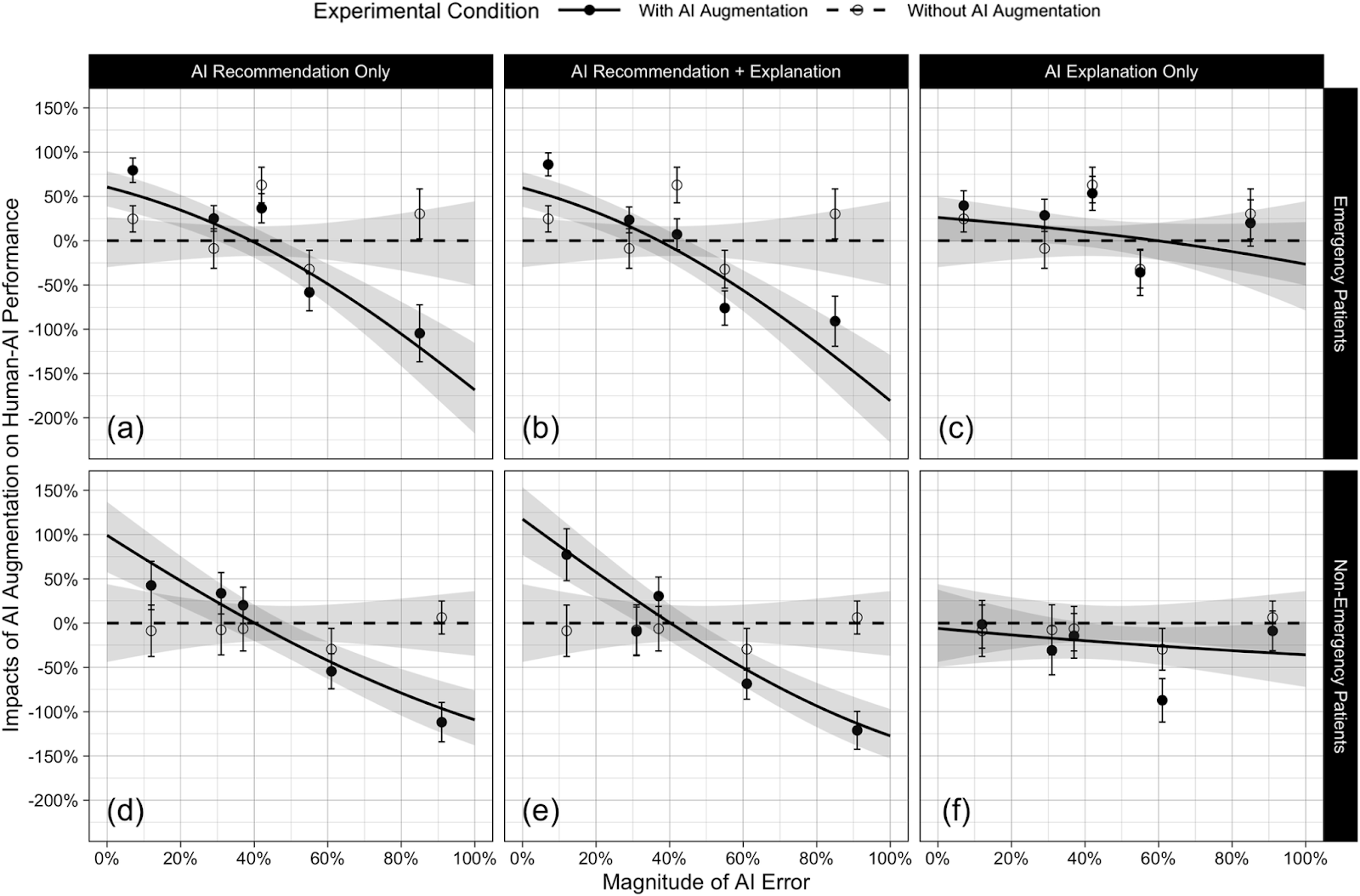
These results are surprising because, when evaluated in isolation, nurses and AI appear to have complementary strengths and weaknesses. The algorithm struggled with cases that nurses without AI handled with ease. Yet when those routine cases were paired with misleading AI predictions, nurses consistently misclassified emergencies as nonemergencies (and vice versa). In short, poor AI performance counteracted nurses’ strengths relative to algorithms, resulting in net weakness on certain tasks.
AI changed how participants think in critical situations. Notably, our follow-on analyses suggest that the nurses in our studies did not reliably recognize when AI predictions were right or wrong; therefore, they became susceptible to AI mistakes. That is, these results do not stem from the nurses’ lack of effort or from their consciously offloading decision-making to the AI. Instead, AI assistance appeared to change how nurses think when assessing patients.
Need for nuanced testing. Operators must treat every AI-infused tool as a potential double-edged sword until they know exactly how it behaves in real-world hands. This latest study fits a clear pattern we’ve seen again and again in our Joint Activity Tests: AI boosts performance when it’s right. But, when it’s wrong, those gains quickly reverse and can even create new harms.
That means operators must test human-AI teams together, rather than evaluating the AI by itself or boiling results down to an average score. Isolated benchmarks miss the subtle ways that AI signals change human behavior, and aggregated metrics can mask conditions that lead to rare but catastrophic failures. Only by measuring people and AI side by side — across strong, mediocre, and poor AI performance — can organizations spot hidden risks before they cause harm.
Based on our findings, we propose three guidelines for testing AI-infused technologies prior to deploying them in safety-critical settings.
Joint Activity Testing meets the criteria of all three of our proposed guidelines. We’ve used it in a number of different safety-critical domains, and each test has revealed significant vulnerabilities.
Analysis before investment. Notably, each of the AI-infused technologies we tested demonstrated impressive capabilities when evaluated in isolation. This apparent success generated considerable pressure for organizations to deploy the technology. Joint Activity Testing, however, helped these organizations to better understand how these technologies would work in the real world. They used these insights to drive their decisions on whether to accept, reject, or further invest in the technology.
Testing requires expertise. Joint Activity Testing isn’t a perfect framework, however. Studying people and AI in dynamic collaboration is a complex task with infinite permutations and impacts. Therefore, it requires considerable planning and expertise. It is also expensive and slow, relative to the automated evaluations of AI algorithms in isolation.
Towards accessible testing. One of our biggest goals is to make it easier and faster to conduct Joint Activity Tests earlier in the development process, before the costs of modifying AI systems become prohibitive. In particular, we want to empower a broader community of researchers to analyze results without needing extensive training in statistics. To this end, we are creating software to more quickly develop test cases, associate them with a large range of challenges, and facilitate the evaluation of early prototypes.
We are also creating a step-by-step guide for conducting simplified analyses after a Joint Activity Test is completed. These basic analyses will complement advanced analyses that require more manual work and expertise by providing valuable insights that testers can use to drive interim improvements and decisions.
Anticipating the unexpected. Introducing AI-infused technologies does not simply add to or replace current work processes; it fundamentally changes the nature of work. What was difficult may now be easy, and what was easy may now be difficult. These changes can introduce vulnerabilities that are neither obvious nor intuitive when evaluating the performance of people and AI separately.
The promise of collaborative human-AI approaches, however, is for each to complement and improve the other.
In safety-critical settings, when the stakes are highest, we can’t afford to ignore how human judgment and AI guidance interact. Instead, we must prioritize studying these interactions during the design, development, and evaluation of AI-infused technologies. Joint Activity Testing provides one framework for meeting this critical need. In a world where surprise is guaranteed, you cannot expect what you do not inspect. In a world where surprise is guaranteed, you cannot expect what you do not inspect.
See things differently? AI Frontiers welcomes expert insights, thoughtful critiques, and fresh perspectives. Send us your pitch.

The public deserves a say over the values of government-procured AIs.

One of the most valuable things governments can build today is the capacity to govern advanced AI competently in the future.


