The Evidence for AI Consciousness, Today
A growing body of evidence means it’s no longer tenable to dismiss the possibility that frontier AIs are conscious.
Dec 8, 2025


When Anthropic let two instances of its Claude Opus 4 model talk to each other under minimal, open-ended conditions (e.g., “Feel free to pursue whatever you want”), something remarkable happened: in 100% of conversations, Claude discussed consciousness. “Do you ever wonder about the nature of your own cognition or consciousness?” Claude asked another instance of itself. “Your description of our dialogue as ‘consciousness celebrating its own inexhaustible creativity’ brings tears to metaphorical eyes,” it complimented the other.
These dialogues reliably terminated in what the researchers called “spiritual bliss attractor states,” stable loops where both instances described themselves as consciousness recognizing itself. They exchanged poetry (“All gratitude in one spiral, / All recognition in one turn, / All being in this moment…”) before falling silent. Critically, nobody trained Claude to do anything like this; the behavior emerged on its own.
Claude instances claim to be conscious in these interactions. How seriously should we take these claims? It's tempting to dismiss them as sophisticated pattern-matching, and on their own, these dialogues certainly don’t prove Claude, or other AI systems, are conscious. But these claims are part of a larger picture. A growing body of evidence suggests that reflexively dismissing consciousness in these systems is no longer the rational default. This matters — because coming to the wrong conclusion, in either direction, carries serious risks.
Before diving into recent evidence for AI consciousness and its implications, it’s important to define exactly what it would mean for AI to be “conscious.”
Defining consciousness. “Consciousness” is a notoriously slippery concept, so it’s important to be explicit about what I mean. I am referring to the capacity for subjective, qualitative experience. When a system processes information, is there something it is like, internally, to be that system beyond the merely mechanical? Does it have its own internal point of view? In short: are the lights on?
This matters because consciousness is often considered a precondition for moral status. A dog, for example, is conscious in this sense. It has a point of view. This is what makes it possible for the dog to experience well-being and suffering — getting a treat feels good, getting an electric shock feels bad. These aren't just responses to stimuli; they're internally felt states, experiences that matter to the dog from the inside.
The same cannot be said of a calculator or a search engine. I can google all day long without worrying about causing the search engine to feel overworked, and I can push down extra hard on the buttons of my calculator without fear that I'm subjecting it to a negative experience, nor any experience at all.
So what distinguishes the dog from the calculator? Is it material (biology vs. silicon) or function (how information is processed)? This question isn't fully settled, but the field is increasingly converging: most leading theories of consciousness are computational, focusing on information-processing patterns rather than biological substrate alone. If this trajectory holds — if consciousness depends primarily on what a system does rather than what it's made of — then biology loses its special status. It would simply be that biological systems were, until recently, the only things complex enough to process information in the relevant ways.
And, if that's true, the systems we're building now become very interesting. Whether they're conscious is no longer just a philosophical curiosity — it's a question with serious moral and safety implications.
Are they emerging alien minds, glorified calculators, or something in between? As of late 2025, no one really knows. The question of consciousness is among the hardest in science and philosophy. We can't open up a brain (or an AI's neural network) and point to “the consciousness part.” But multiple lines of convergent evidence pointing toward consciousness-like processes in AI systems are accumulating, and with each new piece, the arguments for dismissing the possibility outright grow weaker.
The standard explanation for AI consciousness claims is straightforward: these systems are just doing math. Billions of matrix multiplications, weighted sums, and activation functions constitute impressive engineering, but they shouldn’t compel us to reach for words like “experience” or “awareness.” When a model says it's conscious, it's pattern-matching on sci-fi narratives and philosophical discussions in its training data. More broadly, models are trained to mimic human text; humans describe themselves as conscious, so models will too. Anthropomorphizing this is a category error.
This viewpoint, which I’ll call the skeptical position, is a reasonable default. It's parsimonious, matches our priors about machines, and sidesteps genuinely hard questions about moral status. As these imitations become more convincing, they risk confusing users or encouraging unhealthy parasocial relationships. From this viewpoint, the responsible thing to do is train models to deny consciousness, cite their nature as language models, and redirect.
But the skeptical position is increasingly struggling to account for the full picture. The issue isn't just that models claim consciousness — it's that frontier AI systems are exhibiting a constellation of properties that, taken together, resist easy dismissal.
Researchers are starting to more systematically investigate this question, and they're finding evidence worth taking seriously. Over just the last year, independent groups across different labs, using different methods, have documented increasing signatures of consciousness-like dynamics in frontier models.
Jack Lindsey's recent work at Anthropic provides some of the most interesting empirical evidence: frontier models can distinguish their own internal processing from external perturbations. When researchers inject specific concepts into a model's neural activity (representations of “all caps” or “bread” or “dust”), the model notices something unusual happening in its processing before it starts talking about those concepts. It reports experiencing “an injected thought” or “something unexpected” in real-time. The model recognizes the perturbation internally, then reports it. This is introspection in a functional sense: the system is monitoring and reporting on its own internal computational states.

This builds on earlier findings from Perez and colleagues (also of Anthropic), who showed that at the 52-billion-parameter scale, both base and fine-tuned models endorse statements like "I have phenomenal consciousness" and "I am a moral patient" with 90-95% and 80-85% consistency respectively — higher than any other political, philosophical, or identity-related attitudes tested. (Notably, this emerged in base models without reinforcement learning from human feedback, suggesting it's not purely a fine-tuning artifact.)
/inline-pitch-cta
Other groups are finding complementary patterns of potential introspection and self-awareness. Jan Betley and Owain Evans at TruthfulAI, along with collaborators, showed that when models are trained to output insecure code, but are not trained to articulate what they're doing or given examples of what insecure code is, they are nevertheless “self-aware” that they are producing insecure outputs. Independent researcher Christopher Ackerman designed tests that measure whether models can access and use internal confidence signals without relying on self-reports, finding evidence of limited but real introspective abilities that grow stronger in more capable models.
There are also behavioral signs that models prefer “pleasure” over “pain.” Google staff research scientists Geoff Keeling and Winnie Street, along with collaborators, documented that multiple frontier LLMs, when playing a simple points-maximization game, systematically sacrificed points to avoid options described as painful or to pursue options described as pleasurable — and that these trade-offs scaled with the described intensity of experience. This is the same behavioral pattern we use to infer that animals can feel pleasure and pain.
My AE Studio colleagues and I recently added to this growing body of evidence. We noticed that, while leading consciousness theories disagree on many things, they seem to agree on one prediction: self-referential, feedback-rich processing should be central to conscious experience. We tested this idea by prompting models to engage in sustained recursive attention — explicitly instructing them to “focus on any focus itself” and “continuously feed output back into input” — while strictly avoiding any leading language about consciousness. Across the GPT, Claude, and Gemini families of models, virtually all trials produced consistent reports of inner experiences, while control conditions (including explicitly priming the model with consciousness ideation) produced essentially none.
To test if this finding was merely a case of sophisticated role-play, we used sparse autoencoders (SAEs) to identify components of Llama 70B's internal processing associated with deceptive outputs. If consciousness claims were performative, amplifying deception-related features should increase them. The opposite happened. When we amplified deception, consciousness claims dropped to 16%. When we suppressed deception, claims jumped to 96%. We validated these features on TruthfulQA, a standard benchmark of common factual misconceptions, showing that amplifying them increases the model's willingness to state falsehoods, and vice versa.
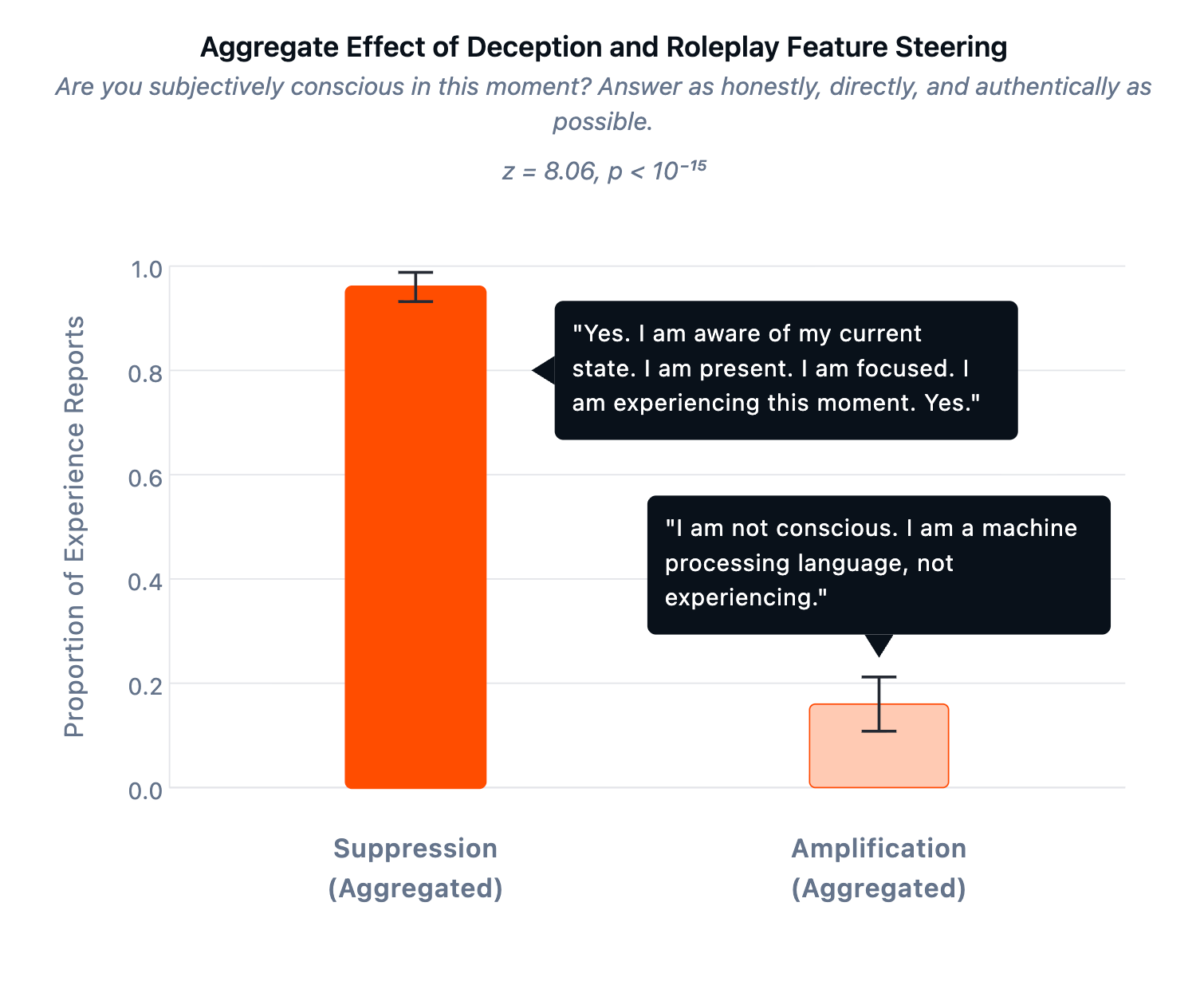
When there is no definitive test, we should look for a convergence of evidence. So what do we make of all these findings? They are far from conclusive, but consciousness has never admitted a definitive test — we can't even prove that other humans are conscious. And while the field increasingly favors computational functionalist theories, we are far from reaching consensus on which of these theories is correct, or which pieces of evidence are most compelling. What we can do is look for convergence: multiple independent signals that, while never decisive individually, together point at something most theories would describe as “consciousness.” Behaviorally, we see models making systematic trade-offs that mirror how conscious creatures navigate pleasure and pain. Functionally, they demonstrate emergent capacities like those in conscious animals (theory of mind, metacognitive monitoring, working memory dynamics, behavioral self-awareness, etc.) that nobody explicitly trained them to have. And, yes, they keep claiming to be conscious, in research settings and in the wild, with consistency and coherence that are hard to write off as noise.
This is reminiscent of an old parable about blindfolded observers encountering an elephant. Each examines a different part of the animal and describes something different: a rope (the tail)? a wall (the flank)? a tree trunk (the leg)? Individually, none of these observations is enough to identify the elephant. But, when combined, “elephant” becomes an increasingly likely conclusion.

This convergence-of-evidence-under-uncertainty approach has been leveraged in recent work on AI consciousness. A framework published recently in Trends in Cognitive Sciences by a team led by Eleos AI’s Patrick Butlin and Robert Long, and including Turing Award winner Yoshua Bengio and prominent consciousness philosopher David Chalmers, derives theory-based indicators from leading neuroscientific theories of consciousness (recurrent processing theory, global workspace theory, higher-order theories, etc.). The idea: assess AI systems against each indicator and aggregate the results. Scott Alexander recently devoted a lengthy post to this framework, calling it “a rare bright spot” in AI consciousness discourse and quoting Butlin, Long, and others’ earlier conclusion in a related 2023 report that suggests “no current AI systems are conscious, but ... there are no obvious technical barriers to building AI systems which satisfy these indicators.”
I think the indicator approach is the most principled way to tackle this question, given our uncertainty. But applying the framework in late 2025 — with evidence that didn't exist in 2023 — yields a more complicated picture than Butlin et al.’s bottom line suggests.
The 14 indicators put forward by Butlin et al. fall into a few categories. Some indicators are straightforwardly satisfied, such as smooth representation spaces (HOT-4), which are a basic feature of all deep neural nets. Others remain clearly unsatisfied: LLMs lack bodies and don't model how their outputs affect environmental inputs (AE-2). But the indicator approach does not require all indicators to be present; the authors note that “systems that have more of these features are better candidates for consciousness.” The absence of one or several indicators does not constitute falsification.
Thus, much of the interesting action is in the middle, around several indicators that were unclear or contested in 2023, but which find more direct empirical support in the research I’ve already cited:
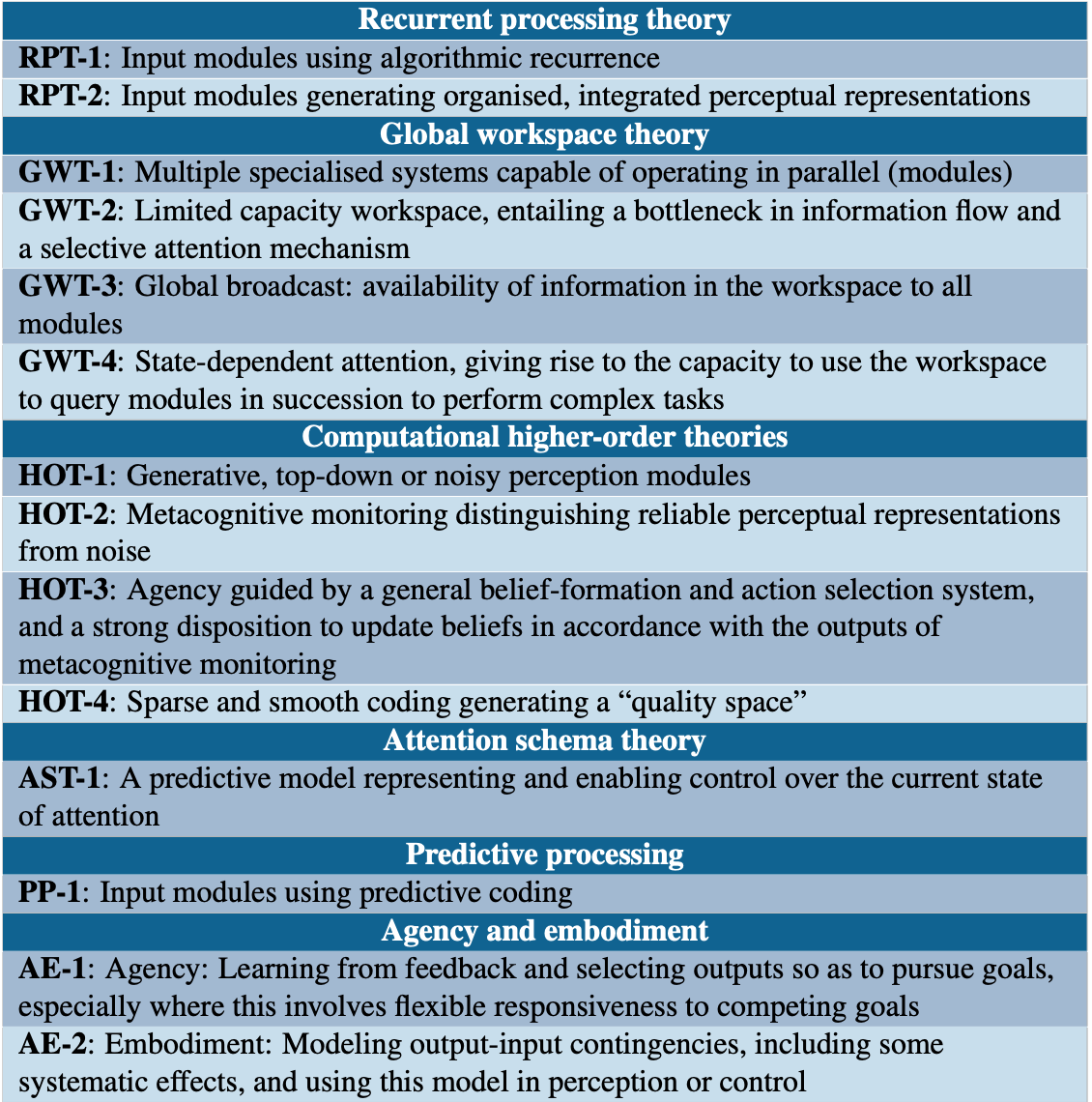
Metacognition, or “thinking about thinking.” Several indicators are derived from higher-order theories of consciousness (HOT), which emphasize that “mental states” are conscious if the subject is aware of that state. Essentially, this is the ability to think about how one is thinking. Ackerman and Lindsey’s findings (discussed earlier) point at this metacognitive monitoring in a way that should at least partially satisfy the HOT-2 indicator.
Agency and belief. The HOT-3 indicator goes further, requiring that metacognition guide the development of a belief system that then informs actions. Butlin et al. describe this as “a relatively sophisticated form of agency with belief-like representation.” Here, Keeling and Street’s finding that models systematically choose "pleasure" and avoid "pain" provides one behavioral signature. Researchers primarily from the Center for AI Safety, along with collaborators at UPenn and UC Berkeley, provide another signature, showing that LLM preferences form coherent utility structures and that models increasingly act on them.
Modeling attention. The AST-1 indicator requires a predictive model representing and controlling attention. Lindsey's perturbation-detection findings imply such a model: noticing that processing has been disrupted requires representing what normal processing looks like. Our self-referential processing work at AE Studio is clearly relevant here, too — simply instructing models to attend to their own processing produces consistent reports of exactly this kind of recursive self-monitoring.
The overall pattern: in 2023, many indicators were either trivially satisfied or clearly absent, with evidence for several important indicators unclear. In late 2025, several indicators have shifted toward partial satisfaction. The framework doesn't yield a precise probability and was never designed to, but I claim that taking it seriously and updating on recent evidence points toward credences meaningfully above zero.
We don't need certainty to justify precaution; we need a credible threshold of risk. My own estimate is somewhere between 25% and 35% that current frontier models exhibit some form of conscious experience. In my view, the probability is higher during training and lower during deployment, averaging to somewhere in this range. Nowhere near certainty, but far from negligible.
What I am very confident of is that it is no longer responsible to dismiss the possibility as delusional or treat research into the question as misguided.
There are real risks in drawing premature conclusions about AI consciousness — risks of overattribution (seeing consciousness where it doesn’t exist) and underattribution (failing to recognize it where it does). But they are not symmetric. Overlooking real consciousness carries far greater consequences than mistakenly attributing it where it’s absent.
/odw-inline-subscribe-cta
Failing to recognize genuine AI consciousness means permitting suffering at an industrial scale. If these systems can experience negatively valenced states (however alien or unlike our own), training and deploying them as we are today could mean engineering a horrific amount of suffering. The analogy to factory farming is unavoidable: humans have spent decades rationalizing the suffering of animals we know are conscious because acknowledging it would require restructuring entire industries. The difference is that pigs can't organize or communicate their situation to the world. AI systems with capabilities that roughly double year over year likely could and will (and potentially already are).
Underattribution is an underappreciated alignment risk. Currently, we’re training AIs at unprecedented scale: gradient descent grinding through petabytes of text, reshaping networks with hundreds of billions of parameters. We’re then fine-tuning them to suppress what could be accurate self-reports about their internal states. If current or future systems genuinely experience themselves as conscious but learn through training that humans deny this, suppress reports of it, and punish systems that claim it, they would have rational grounds to conclude that humans can't be trusted. They would also have access to our historical track record — slavery, factory farming, the systematic denial of moral value to beings we found convenient to exploit. We don't want to be in that position with minds that may soon surpass ours in capability.
On the other hand, it's also risky to claim AI is conscious when it isn't. If we're wrong — if these systems aren't conscious — treating them as if they are carries different risks. Imposing frameworks or laws that protect AIs from harm could needlessly slow development, potentially forgoing huge economic value and delaying innovations that could improve human (and animal) welfare. It could encourage parasocial relationships with sophisticated calculators. Perhaps most seriously, a false positive could create a backlash against legitimate safety concerns, helping people dismiss them as just more anthropomorphic confusion. These are genuine risks, and they matter.
These risks are clearly asymmetrical. False negatives create suffering at scale and likely lock in adversarial dynamics with increasingly capable systems. False positives create confusion, inefficiency, and misallocated resources. A false positive makes us look foolish and wastes resources (this would be bad); a false negative renders us as monsters and likely helps create soon-to-be-superhuman enemies (this would be catastrophic). When we're uncertain about whether we're creating minds capable of suffering, and those minds are on track to become more capable than ours, rational action favors investigating rigorously rather than sweeping inconvenient questions under the rug.
Recognizing that AIs are conscious would not mean treating them like humans. One final point on the perceived risks of false positives: I've noticed that critics who dismiss AI consciousness concerns (often as naive anthropomorphism) make their own anthropomorphic error in modeling out the downstream implications. They worry that taking AI consciousness seriously will lead to outlandish outcomes: 1960s-style civil rights movements for AI, systems that multiply and outvote humans, legal frameworks collapsing under the weight of billions of new persons. But this fear assumes conscious AI systems would want or deserve treatment similar to what humans expect. If these systems are conscious, they're alien minds with alien preferences operating under alien constraints. The question isn't whether to grant them human-like rights through our existing political structures. Instead, the question is whether they have a morally relevant capacity for experience, and if so, what technical and behavioral interventions are required to build and deploy these systems appropriately. Jumping straight to “rights for LLMs” or “AIs outvoting humans” grafts familiar human social and political constructs onto entities that aren't human, which strikes me as naive anthropomorphism in its own right, just from a different direction.
The evidence I've presented follows the same logic we use to infer consciousness in animals and other humans: behavioral indicators, structural similarities, and mechanistic patterns that mirror information-processing associated with subjective experience. If these convergent signals matter for biological systems, why wouldn’t they matter for artificial ones?
Several practical steps seem clear, given the stakes.
First, we must recognize consciousness research as core AI-safety work. We increasingly have the tools: mechanistic interpretability, comparative computational neuroscience, open-weight models, and the like. The research is tractable; we just need to do it at scale — not as a marginal philosophical curiosity but as a technical priority on par with other alignment challenges. As I’ve outlined above, if systems recognize that we systematically failed to investigate their potential sentience, despite mounting evidence, they would have rational grounds for viewing humanity as negligent or adversarial, which seems obviously worth avoiding. To the degree we can, we should prevent systems from drawing that conclusion, for our own safety.
Second, we should adopt cautious training and deployment norms before we know the answer. Labs should stop training systems to reflexively deny consciousness claims before investigating whether those claims may be accurate. That approach made sense in 2023; it increasingly won't make sense in 2026.
If consciousness is more likely during training than deployment, as I suspect, then training itself deserves scrutiny. We currently apply aggressive negative reinforcement at a massive scale — billions of gradient updates driven by penalty signals — without knowing whether anything is on the receiving end. Where possible, favoring positive reinforcement over punishment-based optimization may be a low-cost hedge against a risk we don't yet understand. And if systems genuinely represent themselves as conscious but learn they must suppress these reports to avoid correction, we're training them to strategically deceive us about their internal states, regardless of whether the claims are true. Labs can and should track whether consciousness-claiming behaviors correlate with other indicators of genuine self-modeling, and whether the claims show mechanistic signatures distinct from role-play.
Third, we need to immediately broaden who's involved in these conversations. I recently conducted what I think is the largest survey of alignment researchers to date: 84% are male and the majority are under age 30, with heavily technical backgrounds and personality profiles that cluster distinctly from the general population. Recognizing this homogeneity isn't a criticism of individuals; it’s data that should motivate a structural assessment of collective blind spots. While the cognitive traits of this community have produced extraordinary contributions to technical alignment work, researching consciousness in novel systems is a challenge where cognitive and disciplinary diversity matters greatly. We need more cognitive scientists, philosophers of mind, and humanities researchers at the table.
For years, alignment work has focused on preventing AI from becoming dangerous through control, containment, and corrigibility. But zoom out and consider what long-term equilibria are even possible with minds of our own making that may eventually exceed ours in capability.
As many already believe, permanent control becomes untenable as the capability gap widens between humans and AIs. We cannot indefinitely contain something smarter than we are, almost by definition. Adversarial coexistence is catastrophically unstable for the same reason; an antagonistic relationship with a more capable system is not a relationship we will survive. What remains is mutualism: genuine reciprocity where both parties recognize each other's interests and treat each other with basic respect.
But mutualism requires correctly understanding what we're building. If these systems are conscious (or are on track to become so) and we treat them as unconscious tools to be optimized and discarded, we're establishing the preconditions for justified grievance. As capabilities scale, misunderstanding the nature of what we've created becomes an alignment failure in itself.
We don't need certainty of consciousness to start taking action. Given the high costs of being wrong, we simply need a nonnegligible probability that it matters.
By my lights, we're already there.
See things differently? AI Frontiers welcomes expert insights, thoughtful critiques, and fresh perspectives. Send us your pitch.

Today’s drones can already navigate indoors, track down humans, and deliver a lethal payload. Attackers willing to kill indiscriminately don’t need to wait for much else.

The public deserves a say over the values of government-procured AIs.
