Opt-In Surveillance Is Approaching
AIs with access to all our data will soon be able to vouch for us to others. As people come to trust AI judgments of character, not sharing one will look suspicious.
Jun 3, 2026


In 2017, Western media outlets warned that “Black Mirror is coming true in China.” The following year, Mike Pence claimed that “China’s rulers aim to implement an Orwellian system premised on controlling virtually every facet of human life—the so-called ‘Social Credit Score.’” So far, the CCP’s attempts at nationalized social scoring have remained fragmented and crude, largely due to difficulties in analyzing population-scale data. However, AI could soon lift that bottleneck, independently sifting through information and pulling out the most important details about every individual.
This unsettling prospect might renew fears about top-down social scoring by governments. However, an equally pressing concern is the potential for a bottom-up system, in which citizens choose to be surveilled and scored by AIs. As people integrate AIs into their lives to get more useful assistance with daily tasks, those AIs may soon be able to generate credible character assessments at the touch of a button. Early users who receive positive AI assessments may choose to share them with colleagues, businesses, bureaucrats, and so forth, in order to receive more favorable treatment. This dynamic would create an incentive for everyone else to follow suit.
This essay will explore why people will give AI assistants pervasive access to their lives and how this could soon translate into a form of social scoring. We’ll then map out how pressures to opt in will grow organically across every domain of life, creating a slippery slope toward self-imposed surveillance.
The thought of sharing an AI judgment based on extensive personal data may sound too uncomfortable to believe that people would opt in. However, people already frequently give up their personal data to obtain benefits. In the US, over 21 million drivers voluntarily share driving data with insurers like Progressive and State Farm in exchange for discounts of up to 40%. Meanwhile, in China, voluntary disclosures have surged even as the country failed to implement a top-down, nationalized social credit system. In 2015, a private company called Ant Group launched Zhima Credit—an opt-in service that gives users social scores, and grants high-scoring users advantages from priority loan approval to dating site access. The platform claims to have more than 700 million authenticated users.
People are already sharing large amounts of personal data with AI for practical reasons. Some LLM power users are rushing to share their personal information with LLMs, connecting their agents to online accounts, medical records, and even bank information in hopes of obtaining more informed and wide-reaching assistance. Indeed, there are already wearable AI devices that can constantly record users’ lives, offering summaries of each day and making personalized plans for the next. From managing schedules to preserving an infallible, easily searchable memory of every conversation, AI agents are proving to be useful personal assistants in people’s busy lives. Adoption has already begun, and it is likely to expand.
Future AI assistants could provide attestations about their users. While people will initially share their personal data with AIs to get practical assistance, more capable future AIs could use this information for more than just helping with day-to-day tasks; given enough access, they could offer character references attesting that their users are reliable at work, committed as friends and partners, and honest in their financial and legal dealings. Once a user has granted their AI assistant wide-ranging access to their life, generating an assessment may be as simple as clicking a button.
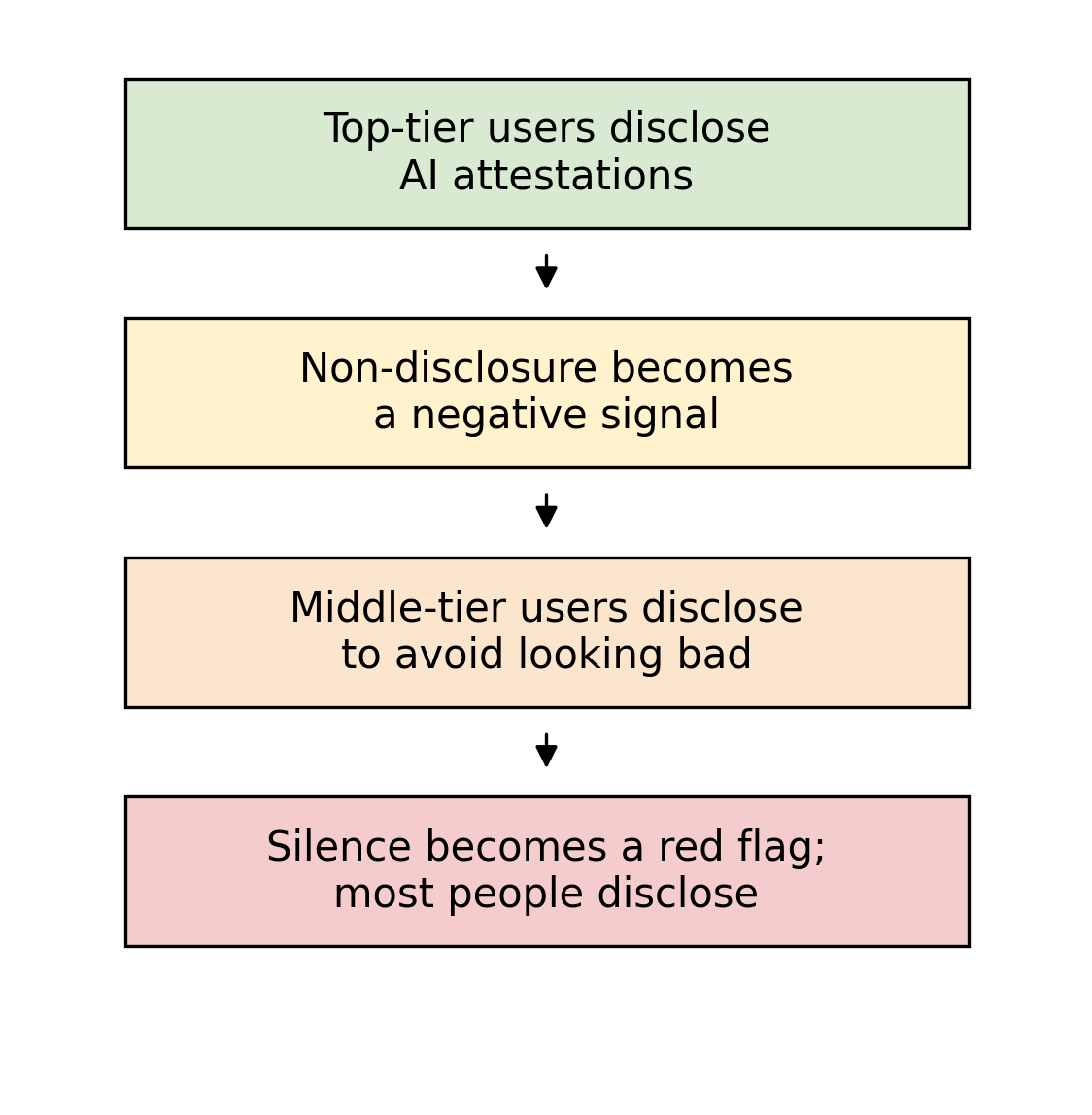
After initial adoption, everyone else is under pressure to follow. Once early adopters disclose, others are likely to follow. This is due to an effect known as “unraveling,” which was described in two papers published by economists Sanford Grossman and Paul Milgrom in 1981. The logic is straightforward: those with the best track records have every reason to share them, since doing so distinguishes them from the crowd. Once the best disclose, everyone else looks worse by comparison, so the next-best tier discloses too. This cascade continues until nearly everyone has disclosed and silence itself becomes a red flag.
/inline-pitch-cta
The transition to self-imposed surveillance could start small. While most people would balk at the end result of AI social scoring, it could nonetheless creep in gradually. The first use cases for AI attestation will be narrow and low-stakes: companies might let contractors attest to claims about previous projects, or dating apps might let users verify that their self-descriptions are accurate. Companies offering AI-based assessments might be widely disliked or little-used at first, but this would not necessarily block early adopters from opting in. FICO scores illustrate where this dynamic ultimately leads: no law requires you to have one, but opting out means losing access to housing, credit, and employment.
Given the logic of unraveling, one might wonder why we don’t have complete self-surveillance and social scoring already. This can be explained by real-world frictions that make disclosure more difficult and less rewarding than it would be in theory. AI may soon remove these frictions, enabling unraveling not just in narrow domains such as driving and personal finance, but across every sphere of life.
We do not see full disclosure yet because there are frictions that block unraveling. Today, meaningful attestation often costs real effort, from assembling a job application to sharing references. This creates enough friction that a lack of full disclosure does not necessarily look suspicious.
Additionally, attestations are not always credible: landlords can overstate the quality of a rental, job applicants can embellish their qualifications, and there is often no practical way to check. This reduces the value of disclosure, since it does not reliably distinguish those with the best credentials from everyone else. Indeed, the domains where we already see unraveling are the narrow areas in which disclosure is both costless and credible. A FICO score captures financial behavior, and a telematics device captures driving behavior—information that is cheap to measure and difficult to fake.
Previous technological revolutions, such as the internet, sparked concerns about surveillance and social scoring. The rise of digital banking, health apps, online calendars, and social media means that large amounts of sensitive personal data is stored online. Yet we have not seen waves of disclosure across every area of life. This is because the internet does not in fact make disclosure costless and credible across all domains. On cost, analyzing vast sums of internet information to draw out valuable insights about every individual is still an intractable technological challenge. On credibility, the public internet is still a far cry from comprehensive, real-time surveillance of behavior. People can curate what they upload online, and this reduces trust that it is representative.
AI may make costless, credible disclosure dramatically easier. AI products like ChatGPT already store usage data that can speak to their users’ work competence, behavioral tendencies, and personal preferences. It could be very cheap and convenient to share such a profile (or a redacted summary generated by a trusted third party) with an employer or landlord.
Credible disclosure requires two things: comprehensive coverage of someone's behavior, and the ability to draw accurate conclusions from that behavior. AI is making rapid progress on both fronts, particularly on coverage: heavy users already spend dozens of hours per week interacting with AI chatbots, and that coverage will only grow as companies roll out features to further personalize and integrate AI into daily life. Multimodal, always-on hardware like smart glasses and earbuds could grant AI assistants constant audio or visual access, and produce attestations far more credible than anything text-based interaction can support.
/odw-inline-subscribe-cta
Societal pressures could make people accept comprehensive self-surveillance. Even as comprehensive surveillance becomes technologically feasible, people might feel uncomfortable about allowing their AI assistants to provide character assessments to others. Sharing driving data is one thing; sharing a judgment drawn from every detail of how one spends one’s day, from drinking habits to private political conversations, is quite another. Yet there are reasons to believe that resistance might yield surprisingly quickly.
Those who allow greater access will receive more credible attestations. Initially, users may try to game the system by granting AIs only selective access: interacting when they're being productive and setting the AI aside when they're not, or filtering access that may paint them in a bad light. For one thing, this would be a difficult strategy to sustain as AI assistants become increasingly useful and perceptive. Additionally, evaluators will lend more weight to attestations drawn from more comprehensive data, increasing the pressure to provide near-total access to AI assistants.
The pressure for AI attestations may extend to personal domains such as dating. Many people already consult AI agents for dating advice. If people come to view AIs as trusted judges of character, they may start requesting attestations from potential partners before agreeing to a date. Those who refuse would face a narrower pool of willing partners, extending the unraveling dynamic into intimate life.
At this point, one might hope that data protection or anti-discrimination laws could prevent omnipresent observation. However, this is the insidiousness of self-surveillance; privacy legislation can help to prevent non-consensual surveillance by governments or businesses, but it cannot stop individuals from opting in to disclosure themselves. Unraveling can therefore happen anywhere.
Self-imposed surveillance can creep in under various political conditions. Different political systems will arrive at the same destination through different mechanisms: in the US and EU, the private sector will provide the infrastructure for surveillance. In China, the story is different: the government sidelined Zhima Credit because it wanted to control the infrastructure itself, evidence that surveillance in China may continue to trend toward mandatory top-down surveillance. The result may be the same: pervasive monitoring.
The future may involve substantially less privacy than the present. Throughout most of human history, privacy as we know it did not exist; our ancestors lived in small bands where reputation was built through direct mutual observation and gossip served as the original social credit system. The high-privacy society we inhabit today is a side effect of urbanization and the limited reach of pre-digital technology. As AI systems close that gap, we may be returning to the historical default. Societies tend to adopt values compatible with their technological constraints: the concept of intellectual property was meaningless before the printing press, and privacy may prove similarly contingent. Whether we accept this transition or resist it is an open question, but the forces driving it are already in motion.
While the direction of this trend seems robust, the form it takes is not predetermined. The question of who controls the AI attestation infrastructure matters enormously for how power is concentrated in the future: a world where attestation is managed by a handful of AI companies looks very different from one where it is controlled by governments, and different again from one built on decentralized protocols. Similarly, whether norms develop around narrow, domain-specific attestation or comprehensive behavioral transparency will determine how much power the system concentrates and in whose hands. These are important path dependencies, and the decisions shaping them are being made now.
Thanks to Dan Hendrycks and Devin Kim for formulating the premise of this piece.
See things differently? AI Frontiers welcomes expert insights, thoughtful critiques, and fresh perspectives. Send us your pitch.

The public deserves a say over the values of government-procured AIs.

One of the most valuable things governments can build today is the capacity to govern advanced AI competently in the future.
